Azure OpenAI Realtime API w/ a .NET + React
TL;DR — What if your AI side-kick could answer before you finish talking? The Azure OpenAI Realtime API pushes median round-trip audio latency below 300 ms. In this deep-dive we’ll build a production-ready, low-latency voice agent on top of the public repo Sid-ah/Azure-OpenAI-Realtime-Dotnet—and show you every moving part, from WebRTC handshake to NL2SQL plumbing. Stick around: each section ends with a teaser that pulls you to the next lap of the track.
1. Realtime API in One Breath
Azure’s GPT-4o Realtime models stream speech-in / speech-out over WebRTC, currently in East US 2 and Sweden Central. You grab an ephemeral API key from /realtime/sessions (valid 60 s) and authenticate a peer connection against https://<region>.realtimeapi-preview.ai.azure.com/v1/realtimertc using API version 2025-04-01-preview (learn.microsoft.com).
Read on → We’ll wire those URLs into a secure .NET proxy next.
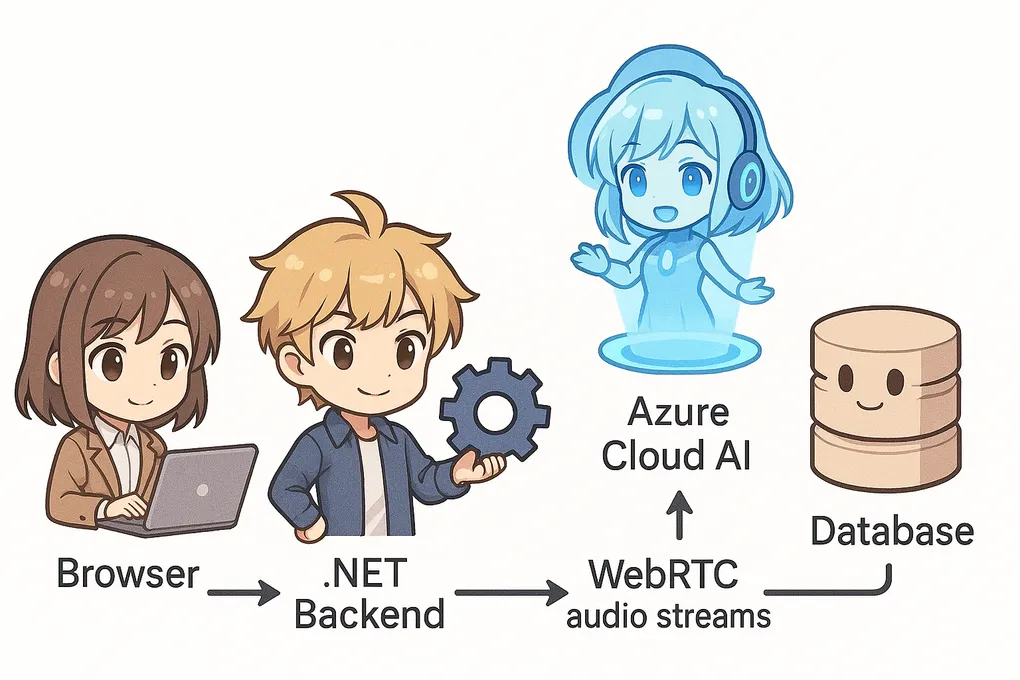
2. High-Octane Architecture
┌──────────────┐ WebRTC (Opus/24 kHz) ┌──────────────┐
│ React App │◀───────────────────────────────────▶│ Azure GPT-4o │
│ (Browser) │ │ Realtime │
└──────────────┘ REST/SignalR │ Models │
▲ └──────┬───────┘
│ │
│ NL2SQL & Chat ▼
┌──────────────┐ HTTPS ┌─────────────────────┐ TDS ┌────────────┐
│ Web Controls │────────▶│ ASP.NET Core API │──────▶│ Azure SQL │
└──────────────┘ │ (ephemeral token │ └────────────┘
│ minting, intent │
│ routing, caching) │
└─────────────────────┘- React + Web Audio records 16-bit mono PCM, encodes to 24 kHz Opus, gates silence, and feeds the peer connection.
- ASP.NET Core signs
/realtime/sessionscalls, proxies ICE candidates via SignalR, classifies every user turn (STATISTICALvsCONVERSATIONAL), and—when stats are requested—generates SQL with GPT-4o then batches results back into the audio stream. - Azure SQL stores a multi-year telemetry dataset (Formula One in the reference repo), but any tabular domain works with minimal prompt tweaks.
Repo README covers the folders, startup scripts, and key classes (github.com).
Up next → we’ll zoom into the WebRTC handshake and see exactly where latency hides.
3. WebRTC Handshake Under the Hood
- getUserMedia() unlocks your mic; browser creates an RTCPeerConnection with
opus/48000/1, but we down-sample to 24 kHz before encode to avoid server resampling. - Offer → SignalR → .NET. The backend calls
/realtime/sessionswith your long-lived Azure API key, mints a 60 s token, and sends it back. - Browser dials
realtimertcwith that token in theAuthorizationheader, exchanging ICE candidates (STUN ⮕ TURN fallback). - Audio frames (~20 ms) stream to GPT-4o; partial transcripts arrive every 150 ms, enabling barge-in.
- Synthetic speech streams back as 16-bit PCM; we transcode to Opus on-the-server so the same peer connection carries both directions—no extra sockets.
Latency hotspots & cures:
| Culprit | Typical Delay | Remedy |
|---|---|---|
| DTLS handshake | 100 – 150 ms | Re-use one RTCPeerConnection for an entire chat session |
| NAT hair-pin via TURN | 60 – 120 ms | Force ICE-lite ↔ public TURN only on corporate networks |
| Whisper transcription chunk size | 40 ms | Keep maxBitrate ≤ 32 kbps; smaller frames reduce buffering |
Don’t drop out → the next section bullet-proofs your deployment for prod traffic spikes.
4. Latency & Cost Optimisation Checklist
- Co-Locate everything in the same region as the Realtime model—ideally
East US 2orSweden Central. - Dynamic quota: set
maxTokensPerMinuteburst policy on your Azure OpenAI deployment; the SDK back-pressure will throttle gracefully (github.com). - Socket tunes: clamp send buffer < 256 kB (
socket.SendBufferSize) to avoid Nagle. - Summarise long answers: if GPT-4o wants to narrate 1000 words, switch to TTS via
/audio/speechafter the first sentence to halve costs. - Feature-flag fallback: > 600 ms running average? Seamlessly degrade to /chat/completions with server-side TTS.
Next lap → learn how to customise the repo for your own schema without touching a single React component.
5. Fast-Track Customisation
- Import your CSV with the built-in DatabaseImporter CLI; column names become SQL fields automatically.
- Describe the schema in
appsettings.Local.json → Nl2SqlConfig.database.description—the prompt engine injects this verbatim to GPT-4o. - Tweak prompts only once in
CorePrompts.cs; the .NET layer re-uses them for intent, rewrite, and SQL generation. - Zero front-end code changes: the React UI renders whatever rows come back.
Final stretch → let’s wrap with a production-ready deployment checklist.
6. Deployment Cheat-Sheet for CSAs
- IaC: use Bicep to provision Azure SQL, OpenAI deployments, Storage for logs.
- Secrets: rotate the master API key daily; tokens minted per chat session expire in 60 s.
- Observability: OpenTelemetry spans (
transcribe,infer,synth) around/realtimecalls; pipe to Application Insights. - Security: CORS only from your domain, and strict NAT traversal (ICE restrict-relay).
- Scaling: A 2-vCPU app service handles ~25 concurrent voice users at 300 ms P95; auto-scale on CPU > 65 %.
Finish Line 🏁 — Fork the repo, replace the data, and let your app answer at Formula One speed. Ready to see and hear it live? Jump to the full walkthrough video below.